과거 가격 흐름 반영
예측 시점보다 앞선 가격 기록만 사용해 피처를 만들었습니다. 최근 7·14·30일 기준 통계를 추가해 짧은 기간의 가격 흐름이 반영되도록 했습니다.
이 프로젝트의 문제 배경과 해결 방식, 핵심 아이디어를 간단히 정리했습니다.
Why We Need
구매 시점을 판단하기 어려움
항공권 가격은 시점에 따라 계속 변하지만, 사용자는 지금 구매할지 기다릴지 판단할 근거를 얻기 어렵습니다.
현재 가격 비교만으로는 부족함
기존 서비스는 현재 시점의 가격 비교에는 유용하지만, 앞으로 더 저렴해질 가능성까지는 충분히 알려주지 못합니다.
미래 흐름 기반 추천의 필요
단순 조회를 넘어, 향후 가격 흐름을 예측하고 ‘언제 사는 것이 유리한지’를 안내하는 서비스가 필요했습니다.
Our Approach
01
데이터 및 피처 구성
노선, 출발일, 구매 시점 데이터를 정리하고 시간대, 출발 임박도, 가격 추세 기반 피처를 구성했습니다.
02
모델 학습 및 파이프라인화
XGBoost 기반 가격 예측 모델을 학습하고, 전처리부터 평가·배포까지 SageMaker Pipeline으로 자동화했습니다.
03
구매 타이밍 추천
향후 30일 후보 시점별 예측 가격을 계산해 가장 유리한 구매 시점 Top 3와 가격 트렌드를 제공합니다.
사용자 요청부터 실시간 추론 결과 반환까지의 흐름과, 학습·배포를 자동화한 ML 파이프라인 구조를 함께 담았습니다.
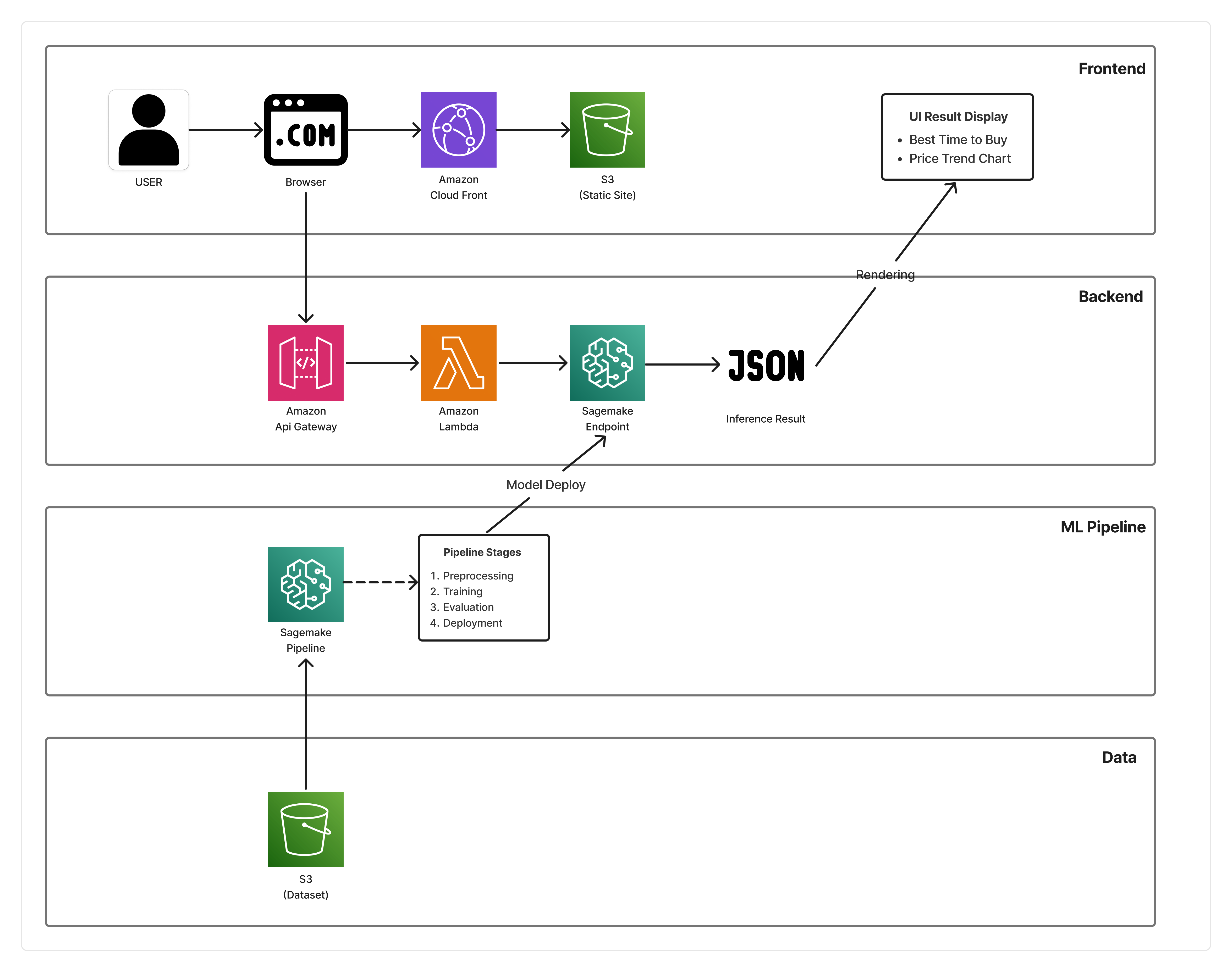
Frontend
CloudFront → S3 (Static Site)
정적 웹 페이지로 빠르게 프로토타입을 배포하고, 추론 결과를 추천 카드와 가격 트렌드 차트 형태로 시각화했습니다.
Backend
API Gateway → Lambda → SageMaker Endpoint
Lambda에서 사용자 입력을 검증하고 30일 구매 후보를 생성한 뒤, SageMaker Endpoint 추론 결과를 가공해 JSON 형태로 반환하도록 구성했습니다.
ML Pipeline
SageMaker Pipeline
전처리, 학습, 평가, 등록, 배포 단계를 자동화하고, MLflow로 실험 결과와 모델 버전을 추적할 수 있도록 구성했습니다.
Data
S3 Dataset & Artifacts
원천 데이터, 전처리 결과, 모델 아티팩트를 계층적으로 저장해 학습과 서빙 과정의 일관성과 재현성을 확보했습니다.
모델 학습, 배포 자동화, 실시간 추론까지 실제 구현 과정에서 중요했던 기술 포인트를 정리했습니다.
시계열 기준으로 피처 구성
예측 시점보다 앞선 가격 기록만 사용해 피처를 만들었습니다. 최근 7·14·30일 기준 통계를 추가해 짧은 기간의 가격 흐름이 반영되도록 했습니다.
가격 분포의 치우침을 줄이기 위해 target에는 log1p 변환을 적용했습니다. 추론 결과를 보여줄 때는 다시 원래 가격 단위로 바꿔 사용했습니다.
실제 예측 흐름과 비슷한 조건에서 성능을 확인하는 것이 중요하다고 판단해, 노선별 시간 흐름을 유지한 상태로 학습·검증·테스트를 나눴습니다.
Preprocess
학습과 추론에 같은 기준을 쓰기 위해 featurizer를 먼저 만들었습니다. 이후 단계에서 같은 피처 구성이 유지되도록 전처리 산출물을 따로 분리했습니다.
Train
XGBoost를 사용해 가격 예측 모델을 학습하고, 전처리 산출물과 route 통계 정보를 함께 묶어 추론에 필요한 모델 패키지로 정리했습니다.
Test
노선별 시간 흐름을 유지해 학습 데이터와 분리된 테스트를 진행했으며 RMSE와 MAE를 기준으로 성능을 확인했습니다.
Register
배포에 필요한 모델 파일과 전처리 산출물을 각각 정리해 등록했습니다. 서빙 단계에서 바로 불러올 수 있도록 아티팩트 구조를 나눠 관리했습니다.
Deploy
등록한 모델을 SageMaker Endpoint에 반영해 실시간 추론이 가능하도록 구성했습니다. 이후 Lambda와 연결해 사용자 요청이 실제 서빙 경로로 이어지도록 정리했습니다.
실행별 파라미터와 메트릭, 아티팩트는 MLflow에 기록해 비교와 추적이 가능하도록 정리했습니다.
SageMaker Pipeline 실행 흐름
서빙 구조와 역할 분리
- route_hash 생성
- 신규 노선 fallback 처리
- featurizer 기반 변환
- XGBoost 추론
- log scale 예측값 반환
요청 처리와 예측 계산이 한곳에 섞이지 않도록, 입력값 정리와 응답 가공은 Lambda에서 맡고 실제 예측 계산은 SageMaker Endpoint에서 처리하도록 나눴습니다.
학습에 없던 노선이 들어오면 route_stats.json의 global fallback 값을 쓰도록 해, 처음 보는 노선에도 응답을 이어갈 수 있게 했습니다.
Lambda 요청 처리 화면
SageMaker Endpoint 상태
01
혼자 설계한 첫 End-to-End MLOps 경험
전처리부터 학습·평가·등록·배포까지 전 단계를 SageMaker Pipeline으로 직접 정의하고, 코드로 작성한 파이프라인을 upsert해 실행·관리하는 구조를 혼자 처음부터 끝까지 구현했습니다. 모델을 만드는 것과 그 모델이 실제로 서빙되는 것은 별개의 문제이며, 단계 간 데이터와 산출물을 잇는 구조 설계가 MLOps의 핵심이라는 것을 체감했습니다.
02
학습 환경과 배포 환경의 불일치 해결 경험
S3 버킷명, MLflow Tracking Server ARN, CORS에서 반복적으로 막혔는데, 모두 학습 시점엔 정상이던 설정이 배포 시점에 어긋나며 발생한 문제였습니다. CloudWatch 로그로 원인을 단계별로 추적해 해결하면서, 로컬에서 동작하는 것과 운영 환경에서 동작하는 것은 다르며 환경 의존 설정을 명시적으로 관리해야 한다는 것을 배웠습니다.